TL;DR: this post explains the MongoDB storage structure we use at Actoboard to efficiently store non periodic time series. Storing one Mongo document for each data point is woefully inefficient, so we store them in fixed-size segments, which speeds things up by more than an order of magnitude.
MongoDB makes the developer's life easier
When we started Actoboard, we decided to use MongoDB to store all our data. I already used it successfully on several projects, and it makes things a lot easier compared to an SQL database when you have a rich data model using a lot of polymorphic structures. You don't have this impedance mismatch between application objects and tables that has produced these object-relational monsters we've loved to hate.
MongoDB is nice for all our configuration data (data sources, widgets, etc): JSON documents are perfect for these fat polymorphic configuration objects, the volume of such data is limited, and the load is mostly read, avoiding the lock problems Mongo has in write-heavy scenarios.
Time series need special attention
Time series data is a different beast, with a write-mostly load of tiny objects consisting of dataset id, timestamp and value. The naive approach of storing each data point as a tiny document will yield poor write performance, as the database has to allocate space for every tiny document holding a data point and add it to the index, which will be almost as large as the actual data.
Read performance will be bad too as the data for a series will be spread in many places on disk, requiring lots of disk seeks when reading a time slice. Deletion of expired data will also create lots of holes on disk, increasing load on the database's space allocator.
We could have used a dedicated database to store time series, but when we started the project with a very small team (1.5 people) we tried to limit the number of moving parts in the architecture. We're ready however to switch to Cassandra when load becomes a problem: its P2P architecture and log-structured storage naturally avoids write contention and stores data on disk in chronological order. But we're not there yet.
The solution is therefore to store many data points in a single MongoDB document. This document has to be pre-allocated (filled with empty values) to avoid its size to change as new data is added, causing it to be relocated on disk. Storing a new data point then consists in doing in-place updates of an empty slot in the document.
The case of non periodic time series
There are many blog posts explaining how to store time series data, but they assume periodic sampling or predefined periodic aggregations. At Actoboard we have widely varying data collection rates ranging from once every minute to once a day. Users can also push values to their custom data sources whenever they want. So we needed something different.
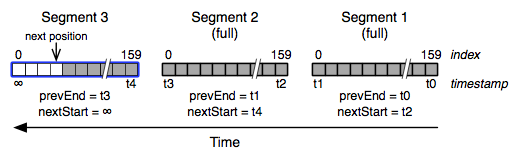
Our time series data is stored in “value segments” containing a fixed number of data points. A segment has the following properties:
- the time series identifier (we use 64 bits integers),
- the end time of the previous segment (more on this later)
- the start time of the next segment (ditto),
- data point times, as an array of 64 bits timestamps,
- data values, as an array of 64 bits floats.
The diagram below illustrates a series with 3 segments, the most recent one being partially filled.
The actual JSON object looks like this:
{
"_id": NumberLong("133506131220758528"),
"series": NumberLong("133814973280288768"),
"owner" : NumberLong("112076101043355649"),
"prevEnd" : NumberLong("1390410338000"),
"nextStart" : NumberLong("1390485108000"),
"time" : [ NumberLong("1390483902000"), NumberLong("1390483299000"), … ],
"value" : [ 24.5, 26.32, … ],
// other housekeeping properties
}
Because of this layout, we’ve put a strong constraint on our time series storage: data points can only be stored in chronological order. Out of order arrival is not allowed to avoid having to insert a datapoint into a filled interval, possibly leading to lots of segment manipulation. In practice this has never been a problem.
Initializing a new segment
When a new segment is created, its time and value arrays are pre-allocated with 160 zeroes. We calculated this length as being the maximum number of data points that can be stored in 4096 bytes, once encoded in BSON.
This 4 KiB size was chosen because MongoDB uses a power-of-two space allocation strategy, and this is also the standard Linux memory page size. Since MongoDB data files are memory-mapped, matching the page size uses the available RAM more efficiently.
On a new segment, the “prevEnd” value is set to the latest timestamp of the previously active segment (or the current timestamp if there’s none). Its “nextStart” is set to MAX_LONG (far far away in the future). More on this in the section on querying below.
Writing a new data point
When new data arrives, we need to know in which segment it should be written to. This is the role of a higher-level “series” object, which contains the active segment’s identifier and the next position to write to in this segment.
Time series object:
{
"_id" : NumberLong("133814973280288768"),
"lastDate" : NumberLong("1419347899000"),
"lastValue" : 27.2,
"segmentId" : NumberLong("254795601416290304"),
"segmentPtr" : 121
}
In the nominal case, writing requires two database updates.
The first update decrements the segment pointer in the time series object and returns the new value. To ensure chronological order, we add the new data point’s timestamp as a query parameter, to prevent any update if it’s not posterior to the last one written.
var series = db.TimeSeries.findAndModify({
query: { _id: seriesId, lastDate: { $lt: time }},
update: { $set: { lastValue: value, lastDate: time }, $inc: { segmentPtr: -1 }},
new: true // return the modified document
})
The result of this operation is an updated object, with the segment index position to write to. We can then perform our second update, storing the data at the correct place:
var fields = {};
fields["time." + series.segmentPtr] = timestamp;
fields["value." + series.segmentPtr] = value;
db.ValueSegments.update(
{ _id: series.segmentId },
{ $set: fields }
);
Now why decrementing the pointer, and not incrementing it? We initialize the pointer with the array’s length. So when the decrement operation returns a negative value, we know that the current segment is full and we must create a new one, without having to care about the actual array length. Fewer magic numbers in the code mean less bugs.
Creating a new segment is the non-nominal case that requires additional writes. It only happens once every 160 values.
Dealing with non ACIDity
MongoDB operations are atomic only at the document level. So what happens if the system crashes once we’ve updated the segment pointer but haven’t yet written the data? We end up with an empty data point in the value segment that has a zero timestamp. We deal with it at the application level by just ignoring such data points.
Also the application may crash after we’ve decremented the pointer and found that a new segment was created, but before it was actually written. In that case, decrementing again the pointer will yield numbers less than -1. Testing for negative values and not just -1 to create a new segment solves the problem.
Querying data
Querying time series data is always done with a time range, particularly with non-periodic time series, since we can’t know the exact time where a data point exists. However in order to draw the series in a given [tmin, tmax] range, we need to also get the data points that are immediately outside of this range, as depicted below:
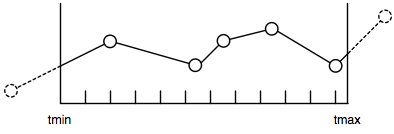
Because of our layout, we fetch entire values segments (160 data points) from the database. Now to get the immediate outside data points, we can’t just query the segments whose data points are in the [tmin, tmax] range.
This is why we store the outer timestamps (previous segment end time and next segment start end time) in a value segment. This allows writing a query that returns segments containing data points right before or right after the wanted time range. Our query is then:
db.ValueSegments.find(
{ series: seriesId, prevEnd: { $lte: tmin}, nextStart: { $gte: tmax }},
{ sort: { prevEnd: 1 }}
)
We then get a set of sorted value segments, and we feed their data points into a pipeline that filters, transforms and aggregates according to the user’s graph configuration.
Performance
Our first tests using the naive approach of 1 document per data point yielded abysmal performance, in the 500 inserts/sec on our integration server.
With this new layout, things are much better, with about 10k inserts/sec. Not bad! Database size is also way smaller because the number of entries in the index has been divided by 160!
We only achieved this number after fixing a bug in Jongo, a thin layer on top of the Java MongoDB driver that allows using the mongo shell syntax to talk to the database. This bug was causing some integer values conversion that led to changing the BSON document layout, defeating the purpose of our value segments.
Conclusion
This may all sound quite complicated, but the code to implement this is rather small and straightforward. The hard part was finding the prevEnd/nextStart trick to fetch the outer data points with no additional requests.
Achieving 10k inserts/sec on a non-sharded setup is more than enough while our user base is still small, even more considering that we rate limit inserts to one per minute, and most of the metrics we collect are updated once every 10 minutes.
And on top of this time series storage, most metrics have an input filter that ensures we only write to the database when the metric value has actually changed, further reducing insertion rate and storage requirements. No need to write the same Twitter follower count every 10 minutes if it hasn’t changed!